

Penguin Solutions Delivers
NVIDIA DGX-Ready Managed Services
Penguin Solutions™ is an expert in managing large NVIDIA DGX clusters.
Penguin Solutions™ has 25 years of experience in managing HPC clusters and 6 years of experience in managing very large NVIDIA DGX clusters. Our years of experience have allowed us to develop unmatched capabilities with running large AI factories. For example, we are helping Meta manage the Meta Research Super Cluster, with over 2000 NVIDIA DGX systems, 16,000 NVIDIA A100 Tensor Core GPUs, 500 PB of storage and 40,000 NVIDIA InfiniBand networking links.

Unlike traditional IT systems, AI infrastructures use different processors, platforms, networks, and involve precision operations. These differences can create gaps in your team’s ability to hit the schedules, performance, and uptime that you need to win.

Penguin continues to provide exceptional uptime and availability for Meta’s large NVIDIA DGX cluster.
“Working in partnership with our implementation partner, Penguin Computing, we improved our overall cluster management. By the time we completed the second phase of building RSC, availability stayed above 95 percent on a consistent basis. This was no small feat given that we added a 10K GPU cluster while concurrently running multiple research projects.” (Meta website, May 18, 2023).
Penguin Solutions is a certified NVIDIA DGX-ready Managed Services partner.
Penguin has designed large NVIDIA DGX clusters, with high-speed NVIDIA InfiniBand networking and optimized storage. We have relationships and expertise with most storage vendors, allowing us to provide bespoke solutions for every customer. Our designs are field proven, scalable, future proof, and they de-risk our customers’ investments.
Tailored
- System, network and storage designs that de-risk deployments and enhance stability and productivity
Proven
- 24 years in HPC
- Over six years building AI Factories
- Deployment of over 50,000 GPUs
Innovative
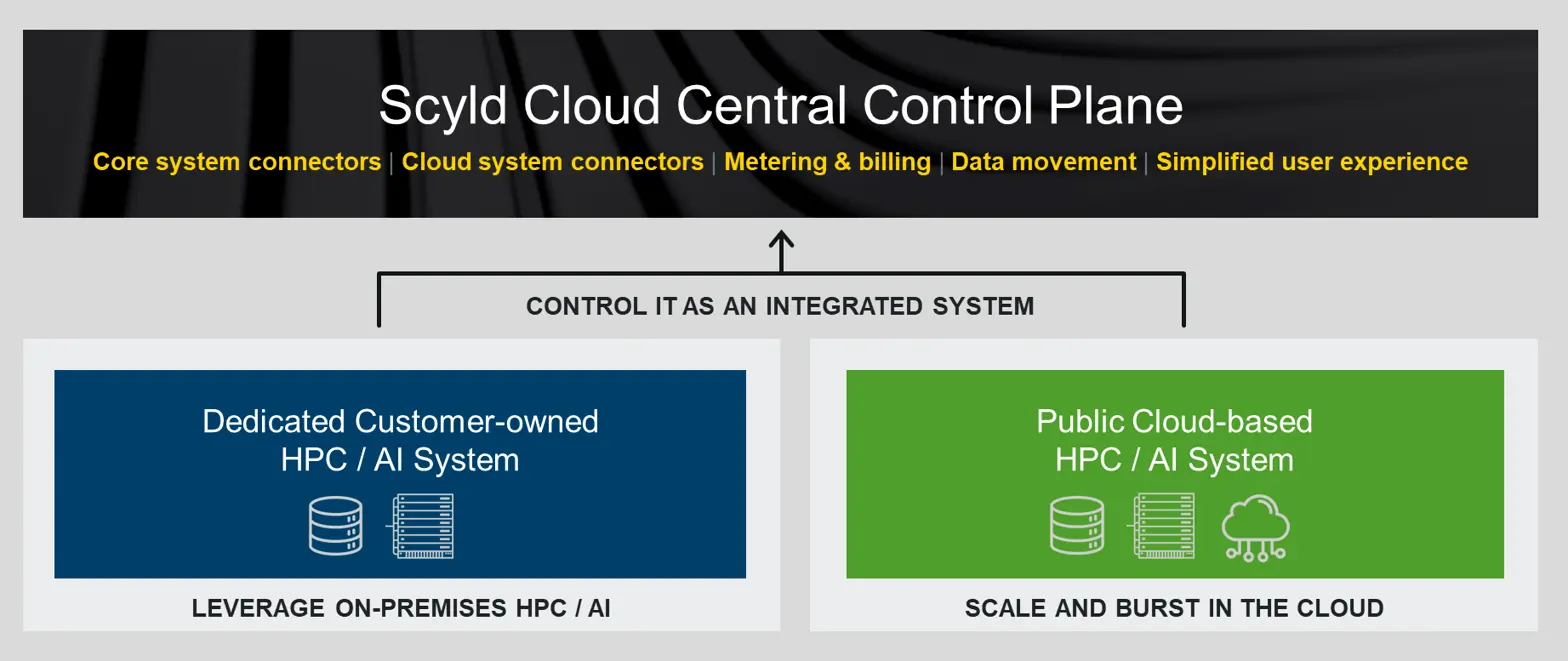
- Hybrid Cloud architectures to accelerate system availability and enable burst and disaster recovery
- Sustainable computing with immersion cooling


Tailored
- Provision AI and HPC server clusters at scale
- Sophisticated factory capabilities to rack, cable, and validate full AI clusters in Penguin’s environment
Proven
- Expert cluster integration
- Validated software stack process eliminating compatibility issues
Innovative
- In-factory burn-in testing and performance validation drives smooth deployments and rapid user access
Penguin is an optimal integration partner offering greater buying power, accurate and rapid installation, comprehensive supply chain management, and predictable project orchestration that addresses the most complex solutions. Our solutions complete full in-factory integration and burn-in testing to ensure that deployed systems are stable and robust at initial deployment.
Thanks to our NVIDIA DGX DevOps and Services teams, Penguin provides:
- Monitoring
- Detection and remediation of issues with all core components (nodes, network, storage, overall cluster, DNS servers, overall compute availability)
- Automated ticketing and integration to customer dashboards
- Automation scripting (Ansible, Python)
- Operational playbooks
- Regular improvements on bandwidth targets and compute targets, node deployment and provisioning

Expert Factory Cluster Integration

Validated Software Stack
Penguin Cluster Provisioning
In-Factory Performance Validation
Tailored
- On-site integration and validation by Penguin’s expert services team
Proven
- System-level testing and project management expertise accelerates system availability and performance
- 700 racks built, delivered, live within 8 months
Innovative
- Penguin-supplied monitoring software continuously validates system health – and maintains cluster availability

White Glove Services

Measurable Success
Production Readiness Reporting

Complete DevOps-based Monitoring
Tailored
- On-site spares inventory and services personnel for maximum system availability
Proven
- Expert support team and Service Level Agreement (SLA) management
Innovative
- Cloud-first deployment model to drive immediate value
- Cloud consumption cost management reporting and guardrails
With Penguin Managed Services, customers enjoy enhanced system availability levels and stable system operation for long-running AI workloads. The result is improved return on investment in AI technology.

Professional Services

Hosting Services

Managed Services