
On-device Artificial Intelligence (AI) is designed for the device to perceive, learn and adapt to user behavior and environments. Vast improvements in recent times in the computing capabilities and hardware accelerators like GPUs and DSPs have fueled the ubiquitous use of AI.
A subset of AI is Machine learning (ML) which is essentially a repeated process of pattern recognition. We as humans learn by observing patterns and over time appreciating their similarities or differences. ML is exactly the same process, where the “training” of neural networks often needs large data and analysis over a prolonged period, which is hugely computing-intensive. A neural network algorithm imitates the neurons of the human brain, which are trained by repeatedly showing data instances that are categorized, computes the most probable result out of the possible outcomes, works backwards through the model and then repeats the process until the algorithm consistently provides correct results. We call this ‘Deep Learning’ owing to the neural networks having multiple (deep) layers that enable learning.
Neural networks need to perform vector and matrix calculations on large datasets, which require a platform that can perform these operations quickly. Qualcomm’s AI Engine hardware includes a Hexagon Vector Processor, an Adreno™ GPU, a Kryo™ CPU and software features includes a Neural Processing (NP) SDK that is designed to optimize the performance of trained neural networks such as TensorFlow and Caffe2 and the ONNX format on devices powered by Snapdragon processors. Efficient and optimized neural processing is key for many use-cases as depicted below. The more deep learning algorithms learn, the better they perform!
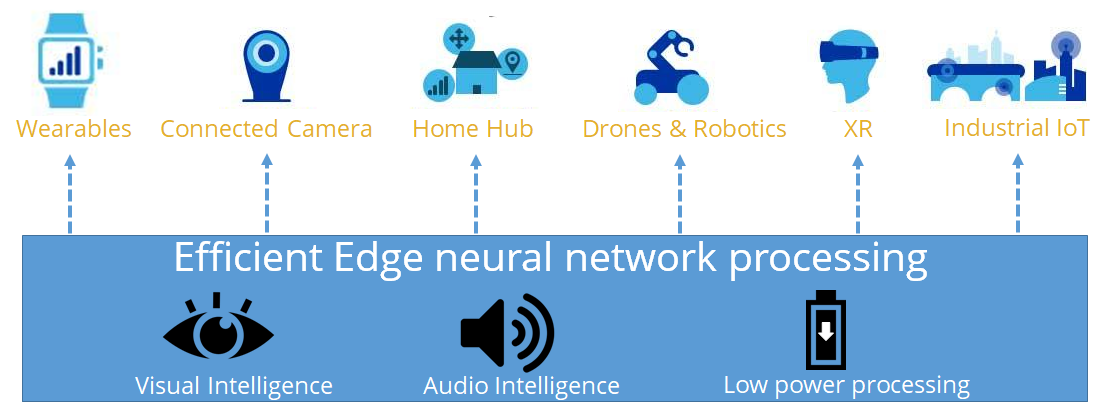
Let us consider a use-case in healthcare where neural processing could be used for parsing wireframes and scene segmentation to achieve privacy. In healthcare, privacy reigns supreme. Strict global regulations prevent recording and transmission of personally identifiable information (PII), and violation of these regulations carries heavy penalties. Unfortunately, this has prevented many IoT technologies from being used in healthcare environments, including traditional hospitals, independent surgical practices, and telemedicine. The ability to run neural networks on edge computing devices is now allowing these technologies to come to market, enabling new standards of care at a low cost. An example where this comes into play is elder care facilities where falls are one of the top causes of injury. Patients may not be able to make someone aware when they have fallen, delaying critical treatment. Traditionally, patient monitoring would use a call button, but these fail in cases where the button cannot be reached, or when the patient has fallen unconscious. Using a camera to monitor the patients is prohibited due to privacy concerns, and automated systems were prohibitively expensive due to the massive computing bandwidth required. Today, manufacturers can run a neural network model on a Snapdragon powered platform to translate high-resolution video input into a wireframe representation of patients in real-time!
The Snapdragon Neural Processing Engine SDK
Apart from acceleration support for the DSP, GPU and CPU, Qualcomm’s SNPE SDK [1] contains:
- Android and Linux runtimes for neural network model execution
- Support for models in Caffe, Caffe2, ONNX, and TensorFlow formats
- APIs for controlling loading, execution and scheduling on the runtimes
- Desktop tools for model conversion
- Performance benchmark for bottleneck identification
- Sample code and tutorials
So if you know how to design and train a model or already have a pre-trained model file and need to run a convolutional neural network in one of the use-case verticals depicted above on a Snapdragon powered platform, the SNPE SDK is a great fit for you! The development workflow is depicted below [1]
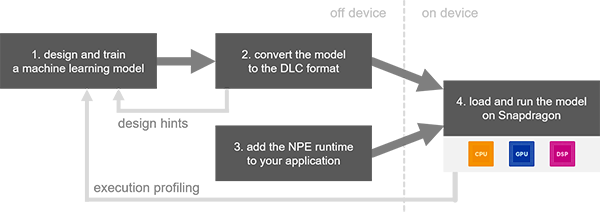
The SDK gives developers the freedom to design and train their networks using familiar frameworks. Once the training is complete, the trained model is converted into a ‘.dlc’ (Deep Learning Container) file that can be loaded into the SNPE runtime. The conversion tool will output information about unsupported or non-accelerated layers, which the developer can use to adjust their initial model’s design. The model workflow is shown below [1]
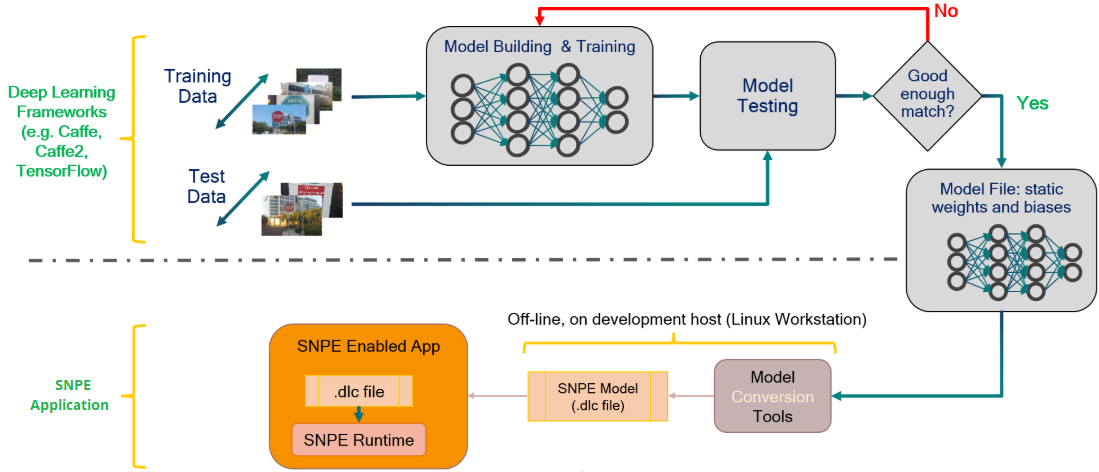
The .dlc file can then be used to perform forward inference passes using one or all of the Snapdragon accelerated compute cores. The SNPE workflow consists of only a few steps:
- Convert the network model to a .dlc file that can be loaded by SNPE.
- Optionally quantize the .dlc file for running on the Hexagon DSP.
- Prepare input data for the model.
- Load and execute the model using SNPE runtime.
It is worthwhile to run performance benchmarks to evaluate how SNPE fares with Android frameworks. The table [2] below summarizes the main aspects of the testing, with performance using TensorFlow-Inception-v3 on CPU normalized to 1x. Inception-v3 (from Mathworks) and AlexNet are convolutional neural networks.
|
TensorFlow Inception-v3 |
Qualcomm NPE
Inception-v3 |
Qualcomm NPE
AlexNet |
| Max performance with CPU |
1x |
1.5x |
3 – 3.5x |
| Max performance with GPU |
3x |
8x |
14x |
| Model format |
.pb |
.dlc |
.dlc |
| Processing also supported on DSP? |
No |
Yes |
Yes |
| API language support |
C++, Java, Python, NodeJS |
C++, Java |
C++, Java |
| Toolkit designed for |
Training and inferencing |
Inferencing |
Inferencing |
Thus, when running inference with the Inception-v3 model, the application built on the Qualcomm Neural Processing SDK processes more frames per second.
Penguin Edge platforms based on Qualcomm Snapdragon processors are designed to enable intelligent on-device capabilities that exploit Qualcomm’s innovations in AI and machine learning algorithms and IPs. All our products allow the running of trained neural networks on-device, without a need for connection to the cloud.
Using the SNPE SDK on Linux OS
The SNPE SDK from Qualcomm is primarily supported on platforms running Android OS. Many product makers prefer using Linux for their application. The SNPE SDK is now enabled on the Linux BSP release on the Snapdragon 845 based Inforce IFC6701 platform. The sequence of instructions listed below are sufficient to enable and use the SNPE SDK on our latest Linux BSP release for the IFC6701 available on our Techweb repository.
Download the latest Debian Linux based BSP package (V0.3) from Techweb and flash the binaries to the Inforce 6701 platform using the instructions from the Release notes that is included in the package.
Steps to verify SNPE:-
Boot up the board and execute the following commands.
root@linaro-alip:~# sudo apt-get update
root@linaro-alip:~# sudo apt-get install autoconf
root@linaro-alip:~# sudo apt-get install libtool
#Build new fastrpc lib
root@linaro-alip:~# cd /home/linaro
root@linaro-alip:~# git clone -b automake https://git.linaro.org/landing-teams/working/qualcomm/fastrpc.git
root@linaro-alip:~# cd fastrpc
root@linaro-alip:~# ./gitcompile
root@linaro-alip:~# make install
#Copy SNPE libraries and model dlc to the target:
root@linaro-alip:~# cp /usr/local/lib/lib* /usr/lib/
#Setup the Inforce 6701 reference design and run SNPE sample (on Target):
root@linaro-alip:~# mount /dev/disk/by-partlabel/dsp_a /dsp
root@linaro-alip:~# cp /home/linaro/snpe/dsp/* /dsp/cdsp/
root@linaro-alip:~# export ADSP_LIBRARY_PATH=/dsp/cdsp
root@linaro-alip:~# export
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/linaro/snpe/lib
root@linaro-alip:~# export PATH=$PATH:/home/linaro/snpe/bin
root@linaro-alip:~# cdsprpcd&
root@linaro-alip:~# cd /home/linaro/inception_v3
root@linaro-alip:~# chmod 777 /home/linaro/snpe/bin/snpe*
#Run on CDSP
root@linaro-alip:~# LD_PRELOAD=/usr/local/lib/libcdsprpc.so snpe-net-run --use_dsp --container ./inception_v3.dlc --input_list target_raw_list.txt
hello snpe-net-run - fastrpc_apps_user.c:1580: Searching for fastrpc_shell_3 ...hello snpe-net-run - fastrpc_apps_user.c:1688: Successfully created user PD on domain 3 (attrs 0x0)-----------------------------------------------------------
Model String: N/A
SNPE v1.30.0.480
-------------------------------------------------------------------------------
Processing DNN input(s):
cropped/notice_sign.raw
Processing DNN input(s):
cropped/plastic_cup.raw
Processing DNN input(s):
cropped/chairs.raw
Processing DNN input(s):
cropped/handicap_sign.raw
Processing DNN input(s):
cropped/trash_bin.raw
##Check results
root@linaro-alip:~# python /home/linaro/snpe-1.30.0.480/models/inception_v3/scripts/show_inceptionv3_classifications.py -i /home/linaro/snpe-1.30.0.480/models/inception_v3/data/target_raw_list.txt -o /home/linaro/inception_v3/output/ -l /home/linaro/snpe-1.30.0.480/models/inception_v3/tensorflow/imagenet_slim_labels.txt
Classification results
cropped/notice_sign.raw 0.144984 459 brass
cropped/plastic_cup.raw 0.980529 648 measuring cup
cropped/chairs.raw 0.311908 832 studio couch
cropped/handicap_sign.raw 0.382252 920 street sign
cropped/trash_bin.raw 0.746154 413 ashcan
References
[1] Qualcomm Technologies, Inc., “Qualcomm Neural Processing SDK for AI,”
https://developer.qualcomm.com/software/qualcomm-neural-processing-sdk.
[2] Qualcomm Technologies, Inc., “Benchmarking the Qualcomm Neural Processing SDK for AI”
https://developer.qualcomm.com/software/qualcomm-neural-processing-sdk/learning-resources/ai-ml-android-neural-processing/benchmarking-neural-processing-sdk-tensorflow
